Solves the system of linear equations A*X=B or A'*X=B. More...
#include "slu_sdefs.h"
Include dependency graph for sgssvx.c:
Functions | |
| void | sgssvx (superlu_options_t *options, SuperMatrix *A, int *perm_c, int *perm_r, int *etree, char *equed, float *R, float *C, SuperMatrix *L, SuperMatrix *U, void *work, int_t lwork, SuperMatrix *B, SuperMatrix *X, float *recip_pivot_growth, float *rcond, float *ferr, float *berr, GlobalLU_t *Glu, mem_usage_t *mem_usage, SuperLUStat_t *stat, int_t *info) |
Detailed Description
Copyright (c) 2003, The Regents of the University of California, through Lawrence Berkeley National Laboratory (subject to receipt of any required approvals from U.S. Dept. of Energy)
All rights reserved.
The source code is distributed under BSD license, see the file License.txt at the top-level directory.
-- SuperLU routine (version 3.0) -- Univ. of California Berkeley, Xerox Palo Alto Research Center, and Lawrence Berkeley National Lab. October 15, 2003
Function Documentation
◆ sgssvx()
| void sgssvx | ( | superlu_options_t * | options, |
| SuperMatrix * | A, | ||
| int * | perm_c, | ||
| int * | perm_r, | ||
| int * | etree, | ||
| char * | equed, | ||
| float * | R, | ||
| float * | C, | ||
| SuperMatrix * | L, | ||
| SuperMatrix * | U, | ||
| void * | work, | ||
| int_t | lwork, | ||
| SuperMatrix * | B, | ||
| SuperMatrix * | X, | ||
| float * | recip_pivot_growth, | ||
| float * | rcond, | ||
| float * | ferr, | ||
| float * | berr, | ||
| GlobalLU_t * | Glu, | ||
| mem_usage_t * | mem_usage, | ||
| SuperLUStat_t * | stat, | ||
| int_t * | info | ||
| ) |
Purpose ======= SGSSVX solves the system of linear equations A*X=B or A'*X=B, using the LU factorization from sgstrf(). Error bounds on the solution and a condition estimate are also provided. It performs the following steps: 1. If A is stored column-wise (A->Stype = SLU_NC): 1.1. If options->Equil = YES, scaling factors are computed to equilibrate the system: options->Trans = NOTRANS: diag(R)*A*diag(C) *inv(diag(C))*X = diag(R)*B options->Trans = TRANS: (diag(R)*A*diag(C))**T *inv(diag(R))*X = diag(C)*B options->Trans = CONJ: (diag(R)*A*diag(C))**H *inv(diag(R))*X = diag(C)*B Whether or not the system will be equilibrated depends on the scaling of the matrix A, but if equilibration is used, A is overwritten by diag(R)*A*diag(C) and B by diag(R)*B (if options->Trans=NOTRANS) or diag(C)*B (if options->Trans = TRANS or CONJ). 1.2. Permute columns of A, forming A*Pc, where Pc is a permutation matrix that usually preserves sparsity. For more details of this step, see sp_preorder.c. 1.3. If options->Fact != FACTORED, the LU decomposition is used to factor the matrix A (after equilibration if options->Equil = YES) as Pr*A*Pc = L*U, with Pr determined by partial pivoting. 1.4. Compute the reciprocal pivot growth factor. 1.5. If some U(i,i) = 0, so that U is exactly singular, then the routine returns with info = i. Otherwise, the factored form of A is used to estimate the condition number of the matrix A. If the reciprocal of the condition number is less than machine precision, info = A->ncol+1 is returned as a warning, but the routine still goes on to solve for X and computes error bounds as described below. 1.6. The system of equations is solved for X using the factored form of A. 1.7. If options->IterRefine != NOREFINE, iterative refinement is applied to improve the computed solution matrix and calculate error bounds and backward error estimates for it. 1.8. If equilibration was used, the matrix X is premultiplied by diag(C) (if options->Trans = NOTRANS) or diag(R) (if options->Trans = TRANS or CONJ) so that it solves the original system before equilibration. 2. If A is stored row-wise (A->Stype = SLU_NR), apply the above algorithm to the transpose of A: 2.1. If options->Equil = YES, scaling factors are computed to equilibrate the system: options->Trans = NOTRANS: diag(R)*A*diag(C) *inv(diag(C))*X = diag(R)*B options->Trans = TRANS: (diag(R)*A*diag(C))**T *inv(diag(R))*X = diag(C)*B options->Trans = CONJ: (diag(R)*A*diag(C))**H *inv(diag(R))*X = diag(C)*B Whether or not the system will be equilibrated depends on the scaling of the matrix A, but if equilibration is used, A' is overwritten by diag(R)*A'*diag(C) and B by diag(R)*B (if trans='N') or diag(C)*B (if trans = 'T' or 'C'). 2.2. Permute columns of transpose(A) (rows of A), forming transpose(A)*Pc, where Pc is a permutation matrix that usually preserves sparsity. For more details of this step, see sp_preorder.c. 2.3. If options->Fact != FACTORED, the LU decomposition is used to factor the transpose(A) (after equilibration if options->Fact = YES) as Pr*transpose(A)*Pc = L*U with the permutation Pr determined by partial pivoting. 2.4. Compute the reciprocal pivot growth factor. 2.5. If some U(i,i) = 0, so that U is exactly singular, then the routine returns with info = i. Otherwise, the factored form of transpose(A) is used to estimate the condition number of the matrix A. If the reciprocal of the condition number is less than machine precision, info = A->nrow+1 is returned as a warning, but the routine still goes on to solve for X and computes error bounds as described below. 2.6. The system of equations is solved for X using the factored form of transpose(A). 2.7. If options->IterRefine != NOREFINE, iterative refinement is applied to improve the computed solution matrix and calculate error bounds and backward error estimates for it. 2.8. If equilibration was used, the matrix X is premultiplied by diag(C) (if options->Trans = NOTRANS) or diag(R) (if options->Trans = TRANS or CONJ) so that it solves the original system before equilibration. See supermatrix.h for the definition of 'SuperMatrix' structure. Arguments ========= options (input) superlu_options_t* The structure defines the input parameters to control how the LU decomposition will be performed and how the system will be solved. A (input/output) SuperMatrix* Matrix A in A*X=B, of dimension (A->nrow, A->ncol). The number of the linear equations is A->nrow. Currently, the type of A can be: Stype = SLU_NC or SLU_NR, Dtype = SLU_D, Mtype = SLU_GE. In the future, more general A may be handled. On entry, If options->Fact = FACTORED and equed is not 'N', then A must have been equilibrated by the scaling factors in R and/or C. On exit, A is not modified if options->Equil = NO, or if options->Equil = YES but equed = 'N' on exit. Otherwise, if options->Equil = YES and equed is not 'N', A is scaled as follows: If A->Stype = SLU_NC: equed = 'R': A := diag(R) * A equed = 'C': A := A * diag(C) equed = 'B': A := diag(R) * A * diag(C). If A->Stype = SLU_NR: equed = 'R': transpose(A) := diag(R) * transpose(A) equed = 'C': transpose(A) := transpose(A) * diag(C) equed = 'B': transpose(A) := diag(R) * transpose(A) * diag(C). perm_c (input/output) int* If A->Stype = SLU_NC, Column permutation vector of size A->ncol, which defines the permutation matrix Pc; perm_c[i] = j means column i of A is in position j in A*Pc. On exit, perm_c may be overwritten by the product of the input perm_c and a permutation that postorders the elimination tree of Pc'*A'*A*Pc; perm_c is not changed if the elimination tree is already in postorder. If A->Stype = SLU_NR, column permutation vector of size A->nrow, which describes permutation of columns of transpose(A) (rows of A) as described above. perm_r (input/output) int* If A->Stype = SLU_NC, row permutation vector of size A->nrow, which defines the permutation matrix Pr, and is determined by partial pivoting. perm_r[i] = j means row i of A is in position j in Pr*A. If A->Stype = SLU_NR, permutation vector of size A->ncol, which determines permutation of rows of transpose(A) (columns of A) as described above. If options->Fact = SamePattern_SameRowPerm, the pivoting routine will try to use the input perm_r, unless a certain threshold criterion is violated. In that case, perm_r is overwritten by a new permutation determined by partial pivoting or diagonal threshold pivoting. Otherwise, perm_r is output argument. etree (input/output) int*, dimension (A->ncol) Elimination tree of Pc'*A'*A*Pc. If options->Fact != FACTORED and options->Fact != DOFACT, etree is an input argument, otherwise it is an output argument. Note: etree is a vector of parent pointers for a forest whose vertices are the integers 0 to A->ncol-1; etree[root]==A->ncol. equed (input/output) char* Specifies the form of equilibration that was done. = 'N': No equilibration. = 'R': Row equilibration, i.e., A was premultiplied by diag(R). = 'C': Column equilibration, i.e., A was postmultiplied by diag(C). = 'B': Both row and column equilibration, i.e., A was replaced by diag(R)*A*diag(C). If options->Fact = FACTORED, equed is an input argument, otherwise it is an output argument. R (input/output) float*, dimension (A->nrow) The row scale factors for A or transpose(A). If equed = 'R' or 'B', A (if A->Stype = SLU_NC) or transpose(A) (if A->Stype = SLU_NR) is multiplied on the left by diag(R). If equed = 'N' or 'C', R is not accessed. If options->Fact = FACTORED, R is an input argument, otherwise, R is output. If options->zFact = FACTORED and equed = 'R' or 'B', each element of R must be positive. C (input/output) float*, dimension (A->ncol) The column scale factors for A or transpose(A). If equed = 'C' or 'B', A (if A->Stype = SLU_NC) or transpose(A) (if A->Stype = SLU_NR) is multiplied on the right by diag(C). If equed = 'N' or 'R', C is not accessed. If options->Fact = FACTORED, C is an input argument, otherwise, C is output. If options->Fact = FACTORED and equed = 'C' or 'B', each element of C must be positive. L (output) SuperMatrix* The factor L from the factorization Pr*A*Pc=L*U (if A->Stype SLU_= NC) or Pr*transpose(A)*Pc=L*U (if A->Stype = SLU_NR). Uses compressed row subscripts storage for supernodes, i.e., L has types: Stype = SLU_SC, Dtype = SLU_S, Mtype = SLU_TRLU. U (output) SuperMatrix* The factor U from the factorization Pr*A*Pc=L*U (if A->Stype = SLU_NC) or Pr*transpose(A)*Pc=L*U (if A->Stype = SLU_NR). Uses column-wise storage scheme, i.e., U has types: Stype = SLU_NC, Dtype = SLU_S, Mtype = SLU_TRU. work (workspace/output) void*, size (lwork) (in bytes) User supplied workspace, should be large enough to hold data structures for factors L and U. On exit, if fact is not 'F', L and U point to this array. lwork (input) int Specifies the size of work array in bytes. = 0: allocate space internally by system malloc; > 0: use user-supplied work array of length lwork in bytes, returns error if space runs out. = -1: the routine guesses the amount of space needed without performing the factorization, and returns it in mem_usage->total_needed; no other side effects. See argument 'mem_usage' for memory usage statistics. B (input/output) SuperMatrix* B has types: Stype = SLU_DN, Dtype = SLU_S, Mtype = SLU_GE. On entry, the right hand side matrix. If B->ncol = 0, only LU decomposition is performed, the triangular solve is skipped. On exit, if equed = 'N', B is not modified; otherwise if A->Stype = SLU_NC: if options->Trans = NOTRANS and equed = 'R' or 'B', B is overwritten by diag(R)*B; if options->Trans = TRANS or CONJ and equed = 'C' of 'B', B is overwritten by diag(C)*B; if A->Stype = SLU_NR: if options->Trans = NOTRANS and equed = 'C' or 'B', B is overwritten by diag(C)*B; if options->Trans = TRANS or CONJ and equed = 'R' of 'B', B is overwritten by diag(R)*B. X (output) SuperMatrix* X has types: Stype = SLU_DN, Dtype = SLU_S, Mtype = SLU_GE. If info = 0 or info = A->ncol+1, X contains the solution matrix to the original system of equations. Note that A and B are modified on exit if equed is not 'N', and the solution to the equilibrated system is inv(diag(C))*X if options->Trans = NOTRANS and equed = 'C' or 'B', or inv(diag(R))*X if options->Trans = 'T' or 'C' and equed = 'R' or 'B'. recip_pivot_growth (output) float* The reciprocal pivot growth factor max_j( norm(A_j)/norm(U_j) ). The infinity norm is used. If recip_pivot_growth is much less than 1, the stability of the LU factorization could be poor. rcond (output) float* The estimate of the reciprocal condition number of the matrix A after equilibration (if done). If rcond is less than the machine precision (in particular, if rcond = 0), the matrix is singular to working precision. This condition is indicated by a return code of info > 0. FERR (output) float*, dimension (B->ncol) The estimated forward error bound for each solution vector X(j) (the j-th column of the solution matrix X). If XTRUE is the true solution corresponding to X(j), FERR(j) is an estimated upper bound for the magnitude of the largest element in (X(j) - XTRUE) divided by the magnitude of the largest element in X(j). The estimate is as reliable as the estimate for RCOND, and is almost always a slight overestimate of the true error. If options->IterRefine = NOREFINE, ferr = 1.0. BERR (output) float*, dimension (B->ncol) The componentwise relative backward error of each solution vector X(j) (i.e., the smallest relative change in any element of A or B that makes X(j) an exact solution). If options->IterRefine = NOREFINE, berr = 1.0. Glu (input/output) GlobalLU_t * If options->Fact == SamePattern_SameRowPerm, it is an input; The matrix A will be factorized assuming that a factorization of a matrix with the same sparsity pattern and similar numerical values was performed prior to this one. Therefore, this factorization will reuse both row and column scaling factors R and C, both row and column permutation vectors perm_r and perm_c, and the L & U data structures set up from the previous factorization. Otherwise, it is an output. mem_usage (output) mem_usage_t* Record the memory usage statistics, consisting of following fields:
- for_lu (float) The amount of space used in bytes for L\U data structures.
- total_needed (float) The amount of space needed in bytes to perform factorization.
- expansions (int) The number of memory expansions during the LU factorization. stat (output) SuperLUStat_t* Record the statistics on runtime and floating-point operation count. See slu_util.h for the definition of 'SuperLUStat_t'. info (output) int* = 0: successful exit < 0: if info = -i, the i-th argument had an illegal value > 0: if info = i, and i is <= A->ncol: U(i,i) is exactly zero. The factorization has been completed, but the factor U is exactly singular, so the solution and error bounds could not be computed. = A->ncol+1: U is nonsingular, but RCOND is less than machine precision, meaning that the matrix is singular to working precision. Nevertheless, the solution and error bounds are computed because there are a number of situations where the computed solution can be more accurate than the value of RCOND would suggest. > A->ncol+1: number of bytes allocated when memory allocation failure occurred, plus A->ncol.
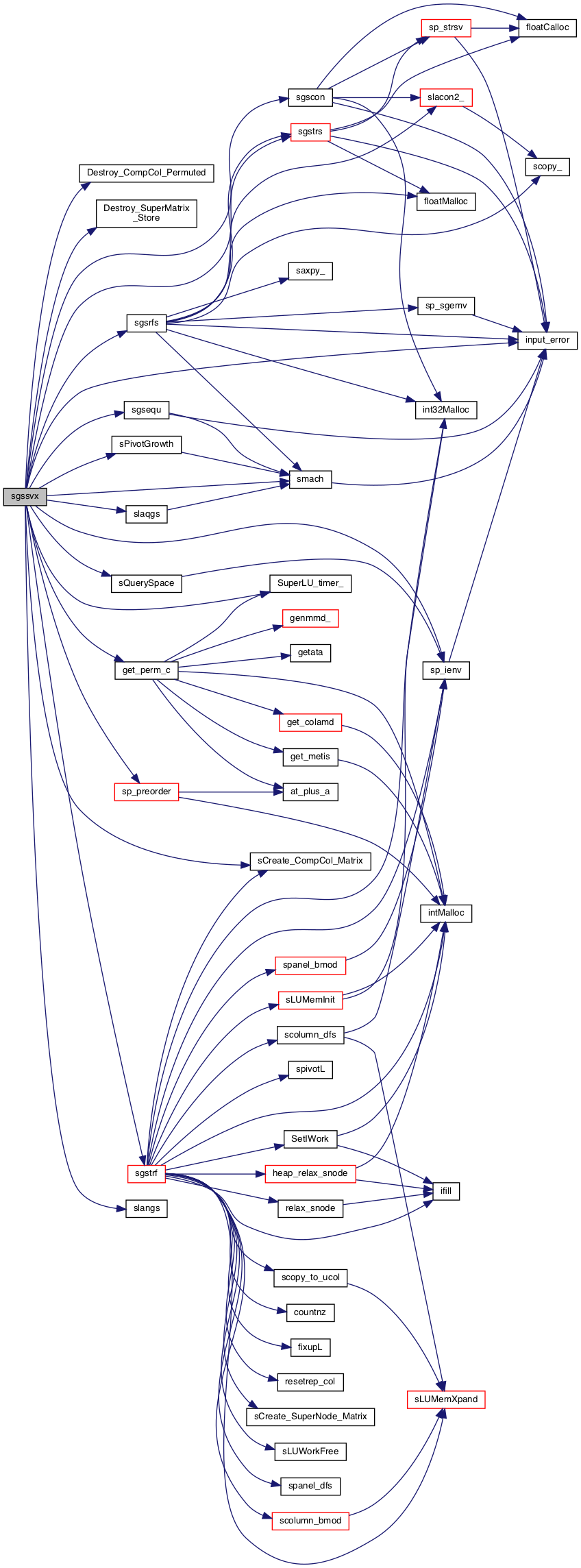
Here is the call graph for this function: